InlineStrings.jl: Fun with Primitive Types and LLVM in Julia
Ok, first post in a while. Sorry. Some of you know me; I come and go on the blogging front. Here's my latest attempt to restart blogging efforts, and insider tip: the more requests for blogposts, the more motivated I am to write!
Oh man I'm excited to write about this. The InlineStrings.jl Julia package. This was probably one of the most fun little projects I've worked on in the last little while. Let's jump right into the background and then on to the fun how-it-was-implemented stuff.
Why InlineStrings?
The Julia language has a built-in garbage collector that works via "world-age aging/sweeping". That means that at defined moments (i.e. usually when allocating), the GC will "sweep" over live objects, recording their "age", and how many references exist to them. Objects without references to them will be "cleaned up", or in more technical terms, have the memory allocated for them freed. Note that this "GC book-keeping" only applies to what I'll call "reference types"; in technical Julia terms, which I believe corresponds to whether isbitstype(T) returns false. I.e. if a type is isbitstype, then it isn't GC-managed, but always lives on the stack instead.
Ok, why the GC background here? Well, when working with data, you often work with lots of String type values. Whether they come from a csv file, database, or other data ingestion, String values are "reference objects" in that their memory is managed by the garbage collector, while other common "data" types aren't: floats (Float32, Float64), integers (Int32, Int64), or booleans (Bool). And so we arrive at our story's main conflict: working with "big data" number of Strings introduces non-trivial GC overhead from reference-object book-keeping. "Big data" in that statement is purposely a little vague as this depends somewhat on runtime hardware specs, but in general, once we get into the "millions of Strings" size of data, GC pauses for sweeping/reference checking can introduce noticeable overhead, which makes working with large amounts of Strings kind of annoying!
(As a side-note, even if just for myself: I'd love to dig around and see if/how other languages/data framework have dealt with this. My impression is that languages probably haven't dealt with this problem nearly as much as data frameworks, which in my mind include database implementations, data ingestion engines, or data processing frameworks like Pandas/polar-rs/data.table/etc. For languages, there's also the question of how memory is even handled: 100% manual like C? Ref-counted? Precision ownership tracking a la Rust? It's the kind of question that is tied very closely to a language's garbage collection implementation and hence, not easy to generalize very much between static vs. dynamically typed languages).
Alright then, so what is to be done? How do we process millions of strings without completely overwhelming the garbage collector? Enter InlineStrings.jl.
InlineStrings Representation
primitive type InlineString3 <: InlineString 32 end
There it is; the type definition of InlineString3, or String3 for short. Let's walk through what's going on here, step by step:
primitive type, woah, woah, woah, what the heck is this? We're defining our own primitive type, don't worry, we'll walk through what that means in more detail. Yes, it's low-level and not common.InlineString3 <: InlineString: giving our type a name and saying it's a concrete subtype of the abstract typeInlineString; the subtyping will come in handy later on when we want to write generic functionality on any size of inline string32: the number of raw bits our primitive type is defined to take upend: that's it! That's the end of our type definition; primitive types don't have fields because they're just plain bits.
Ok, so we defined a custom 32-bit primitive type named InlineString3 that subtypes InlineString. So what was a primitive type again? Primitive types are the lowest-level way to define types in Julia, usually just for bootstrapping Julia itself. As mentioned above, they don't have fields, because they're literally just a defined number of bits, and then it's up to you and your fancy software to determine how those bits are interpreted. (The most widely known standards for bit interpretation are probably two's complement for integer representation, and the "IEEE" representation for decimals). Ok, so we just have to come up with our own custom interpretation of bits then, right? No biggie? 😅.
Well, we don't have to go too crazy here. We have a lot we can build on with the UTF-8 variable width codeunit encoding, which the Julia builtin String already follows natively. Each codeunit is 1 byte, or 8 bits, and codepoints can be interpreted by looking at a series of codeunits. And there's already a lot of existing code for doing all that, so we just need to worry about how we pack those codeunits into our predefined number of bits. Easy!
Wait, wait, wait, hold up, something doesn't add up here; we said InlineString3 was defined as 32-bits, right? So why isn't it called InlineString4?? Very good question, my young apprentice, let's discuss: we not only need to store UTF-8 codepoints in our primitive type bits, but we also need to store the string length. As is probably obvious to you, this "primitive type" representation is different than how you would expect a normal String to be stored. For the string "hi", there are 2 codeunits, which can be represented as unsigned 1-byte integers like [0x68, 0x69]. For a String, the representation is basically that: we store the length 2, then the 2 bytes [0x68, 0x69]. For our primitive type InlineString3, however, we already know it's going to take up 32-bits no matter what, but we still need to store the codeunits themselves, as well as the length, in case our string doesn't have codeunits equal to the # of bits available. Back to our example, "hi", we're going to store the two codeunits [0x68, 0x69] in the 2 highest bytes (16 bits) of our 32-bits, and then store 0x02 in the lowest byte, so we can keep track that we've only used 2 of our 3 possible bytes. For my fellow visual learners out there, here's a breakdown of the individual bits for "hi" stored as an InlineString3:
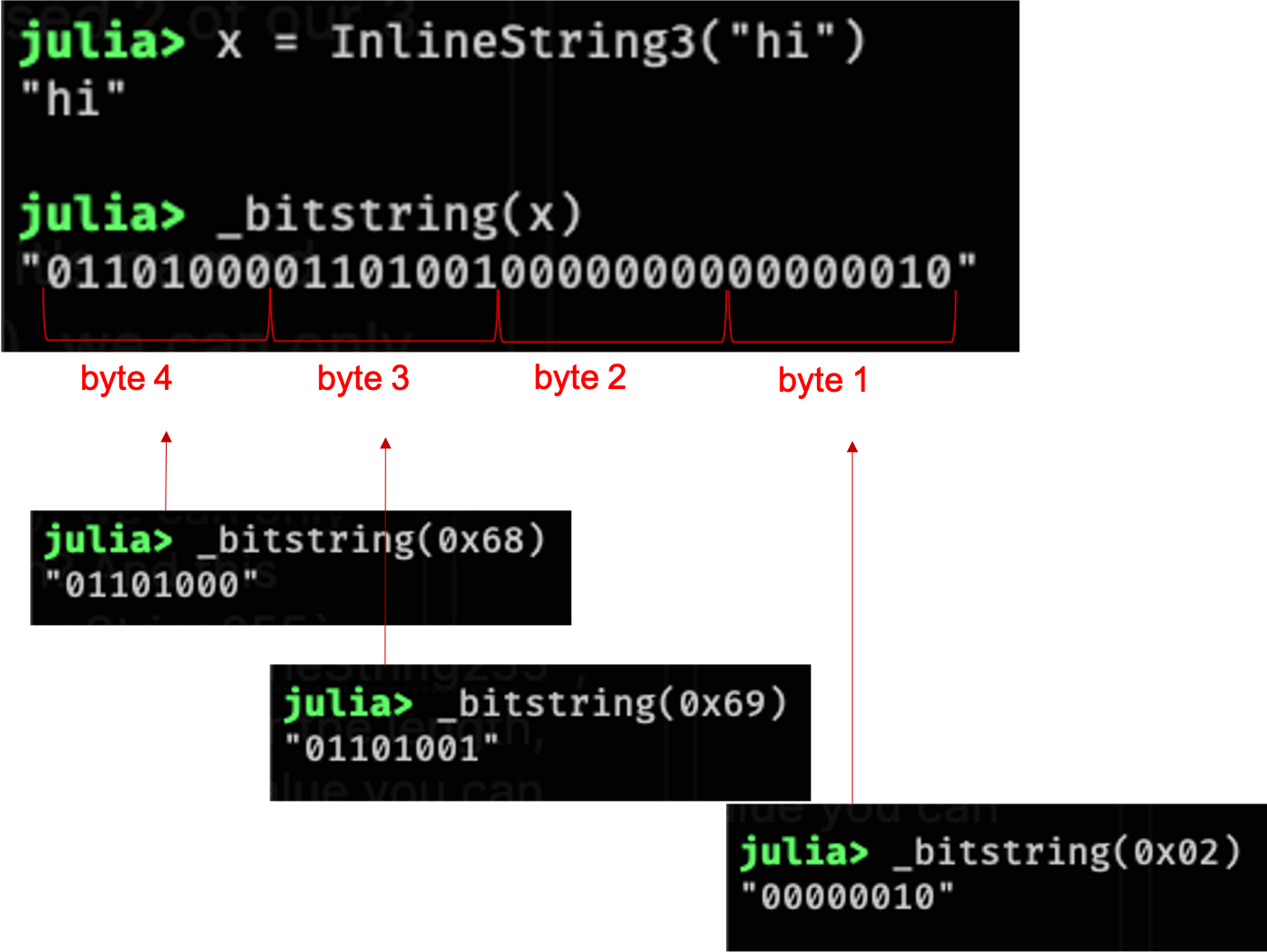
And so hopefully the answer to the question didn't get too lost in there: it's named InlineString3 because even though we have 4 bytes available (32 bits), we can only use up to 3, because we reserve the lowest byte for our length. Nifty, eh? And this definition holds for all our InlineString subtypes, all the way up to InlineString255, which is actually 256 bytes large, but we still keep that lowest byte for the length, which conveniently pretty much matches the largest possible integer value you can store in a single byte (using two's complement): 256.
Ok, but we still haven't come full circle back to the original GC overhead with regular Strings; ah, see that's where our use of primitive type comes in again. Primitive types are just plain bits, as you'll remember, and hence there's no need for the GC to "manage" these kinds of objects, because they'll only ever live on the stack. So this is like the most perfect solution for strings ever, right? Right?? Well, as you may also remember in our simple little example of "hi", that was only 2 bytes, but our String3 type always takes up 4 bytes. Now, these are small enough that in the grand scheme of things, and with how Strings are represented in core Julia, the difference here probably isn't going to really be noticeable, but let's say we extend our usage of these inline strings to an entire Array of them, which means we continue to see the difference of these being defined as isbitstypes instead of reference types. For Array in Julia, reference elements will just have the pointer to their heap memory stored as the array element, while isbitstype (ok, it's a tad more complex that just isbitstype, but we'll save that for another time) are stored "inline" (a pun on purpose), i.e. a String3 will have 4 bytes stored for each element for the entire array and to get individual String3 objects, we just "reinterpret the bits" at that element byte offset.
But, but, but.......let's say we have an Array of InlineString31, which is 8x the size of our little InlineString3, yet perhaps the individual elements have a high variance in terms of their length. So an InlineString31 with length 1, 2, or 3, while some are length 30 or 31. For an InlineString31 with length 1, that's 30 whole bytes of wasted space! And for an Array like this of millions of elements, that can quickly add up to a lot of wasted space relative to how a normal String is stored. So no, unfortunately InlineStrings are not a silver bullet for string representation, there are still trade-offs as usual. But it can be the right tool for the job for a lot of data processing workflows.
InlineStrings Implementation
Ok, cool, so now we understand the why and how these things are represented, but the astute reader may still be wondering, how the heck are we supposed to be manipulating 2048 raw bits?? (in the case of String255). It's a great question! Julia has the mostly straightforward/standard set of bit manipulation functionality for integers and floats, but if you try and do InlineString("hi") >> 1, you get the standard method-not-defined error. But how do these operations work for integers under the hood?? Let's take a peek:
julia> @which 0x01 >> 1
>>(x::Union{Int128, Int16, Int32, Int64, Int8, UInt128, UInt16, UInt32, UInt64, UInt8}, y::Int64) in Base at int.jl:491
and now the definition at int.jl:491:
>>(x::BitUnsigned, y::BitUnsigned) = lshr_int(x, y)
Hmmmm......what is this lshr_int thing?
julia> Base.lshr_int
lshr_int (intrinsic function #45)
"intrinsic function #45"? In Julia, there are certain types and functions that are "built-in", defined in the C source code and are "just there" when you first start bootstrapping Julia. lshr_int actually corresponds to the LLVM native instruction lshr, which is the "logical shift right" instruction. Ok! So when you do 0x01 >> 1 in Julia, there's a generic method defined on Integers for the >> operator that eventually ends up calling the LLVM lshr instruction to actually logically shift right the bits of the integer. Cool! Wait, what's that? We can actually see the LLVM code that gets generated here?
julia> @code_llvm 0x10 >> 1
; @ int.jl:491 within `>>`
define i8 @"julia_>>_3672"(i8 zeroext %0, i64 signext %1) #0 {
top:
; ┌ @ int.jl:471 within `<=`
%2 = icmp slt i64 %1, 0
; └
; @ int.jl:491 within `>>` @ int.jl:485
%3 = trunc i64 %1 to i8
%4 = lshr i8 %0, %3
%5 = icmp ugt i64 %1, 7
%6 = select i1 %5, i8 0, i8 %4
; @ int.jl:491 within `>>`
; ┌ @ int.jl:85 within `-`
%7 = sub i64 0, %1
; └
; ┌ @ int.jl:486 within `<<`
%8 = trunc i64 %7 to i8
%9 = shl i8 %0, %8
%10 = icmp ugt i64 %7, 7
%11 = select i1 %10, i8 0, i8 %9
; └
%12 = select i1 %2, i8 %11, i8 %6
ret i8 %12
}
Woah! Do you see the instruction there? %4 = lshr i8 %0, %3. There it is! Very cool!
So what does this all have to do with InlineString bit manipulation? Well.....in the LLVM documentation for the lshr instruction, it doesn't mention any restriction on the size of the input arguments:
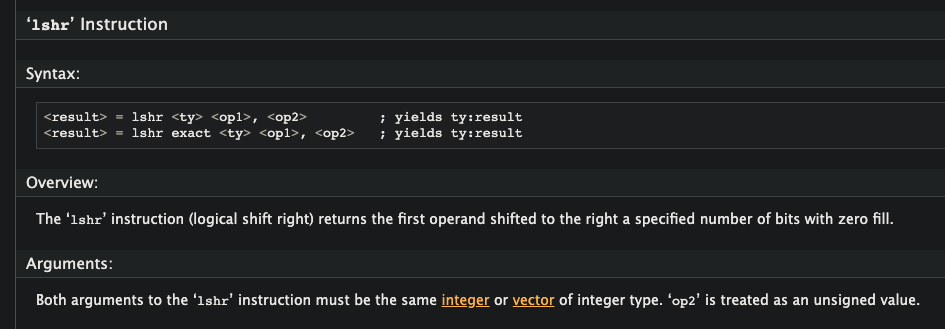
And so.....what if we could call this lshr instruction on our InlineString bits? It turns out, we can!
julia> lshr(x, i) = Base.lshr_int(x, i)
lshr (generic function with 1 method)
julia> @code_llvm lshr(InlineString("hi"), 1)
; @ REPL[82]:1 within `lshr`
define i32 @julia_lshr_3692(i32 zeroext %0, i64 signext %1) #0 {
top:
%2 = trunc i64 %1 to i32
%3 = lshr i32 %0, %2
%4 = icmp ugt i64 %1, 31
%5 = select i1 %4, i32 0, i32 %3
ret i32 %5
}
Look at that! We get our very own lshr LLVM instruction that operates on our InlineString3 object! And this works because to LLVM, it just knows that an InlineString3 is just 32-bits of data, as can be seen in our lshr instruction call with the arguments being i32, or Int32. And Julia just lets us "pass" our custom bits object down to LLVM! Very cool.
And following this same pattern, we can tap into a host of these LLVM instructions to do all sorts of useful bit manipulations on our inline strings, including:
trunc: truncate a larger bits object down to a smaller bits objectzext: "grow" a smaller bits object up to a larger bits objector/and: bitwise OR/AND operationsshl: shift bits left a specified # of bitsbswap: swap the endianness of a bits object (i.e. reverse the bits) And so using these LLVM "primitives", we can do all the operations needed to create, adjust, and manage our inline strings!
And here's the really cool part: this even works on our larger String31/String63/String127/String255 types. Think about it: in Base Julia, integer sizes go up to Int128/UInt128, which are 16-byte integers using the 2's complement bit representation. But String31 is twice as big at 32-bytes or 256 bits! But the LLVM instructions don't have restrictions on input sizes. Seriously? Yeah, check this out:
julia> @code_llvm lshr(String31("hi"), 1)
; @ REPL[82]:1 within `lshr`
define void @julia_lshr_3724(i256* noalias nocapture sret(i256) %0, i256 zeroext %1, i64 signext %2) #0 {
top:
%3 = zext i64 %2 to i256
%4 = lshr i256 %1, %3
%5 = icmp ugt i64 %2, 255
%6 = select i1 %5, i256 0, i256 %4
store i256 %6, i256* %0, align 8
ret void
}
To LLVM, our String31 type is just the same as an i256, or an integer with 256 bits! And this works even up to our String255 type:
julia> @code_llvm lshr(String255("hi"), 1)
; @ REPL[82]:1 within `lshr`
define void @julia_lshr_3728(i2048* noalias nocapture sret(i2048) %0, i2048 zeroext %1, i64 signext %2) #0 {
top:
%3 = zext i64 %2 to i2048
%4 = lshr i2048 %1, %3
%5 = icmp ugt i64 %2, 2047
%6 = select i1 %5, i2048 0, i2048 %4
store i2048 %6, i2048* %0, align 8
ret void
}
Where LLVM just sees the String255 object as a 2048-bit integer!
Now, if we consider the native CPU instruction set, they're obviously not shipping native 2048-bit instruction sets (the largest I'm aware of out there are 512-bit), so at some point, LLVM is switching, depending on hardware, to software implementations of these instructions, but what's convenient for us is that it just takes care of all that for us! All we have to say is, "hey, I'd like to shift this 2048-bit integer bits to the right by 8" and LLVM takes care of the rest. Very nifty and very handy for making a simple implementation on these custom bits primitive types.
Radix sort
Ok, so we've had some fun with bits types and LLVM instructions, and this post is getting pretty long, so I'll try to wrap it up here by just mentioning a few more fun things.
One of the really cool things we can do with our fixed-bit-width string representation is utilized radix sorting, which can lead to big speedups vs. traditional string sorting (using merge sort, for example). Feel free to read up on radix sorting here, but the general gist is that you do a pass over the elements, chunk up each element into a fixed bit-width (8-11 bits), and accumulate count the number of unique bit patterns you see for each bit chunk. Afterwards, we can use these "binned bit counts" to effectively sort each element by doing a cumulative sum of the counts over the bit patterns and seeing where the bit pattern of each element lies. As we process further bit chunks, ties will be broken and the eventual result is all our values sorted. This ends up being great for inline strings when there are enough elements. As a quick visual for the kind of speed ups we can get even just for String3 using a radix sort vs. merge sort:
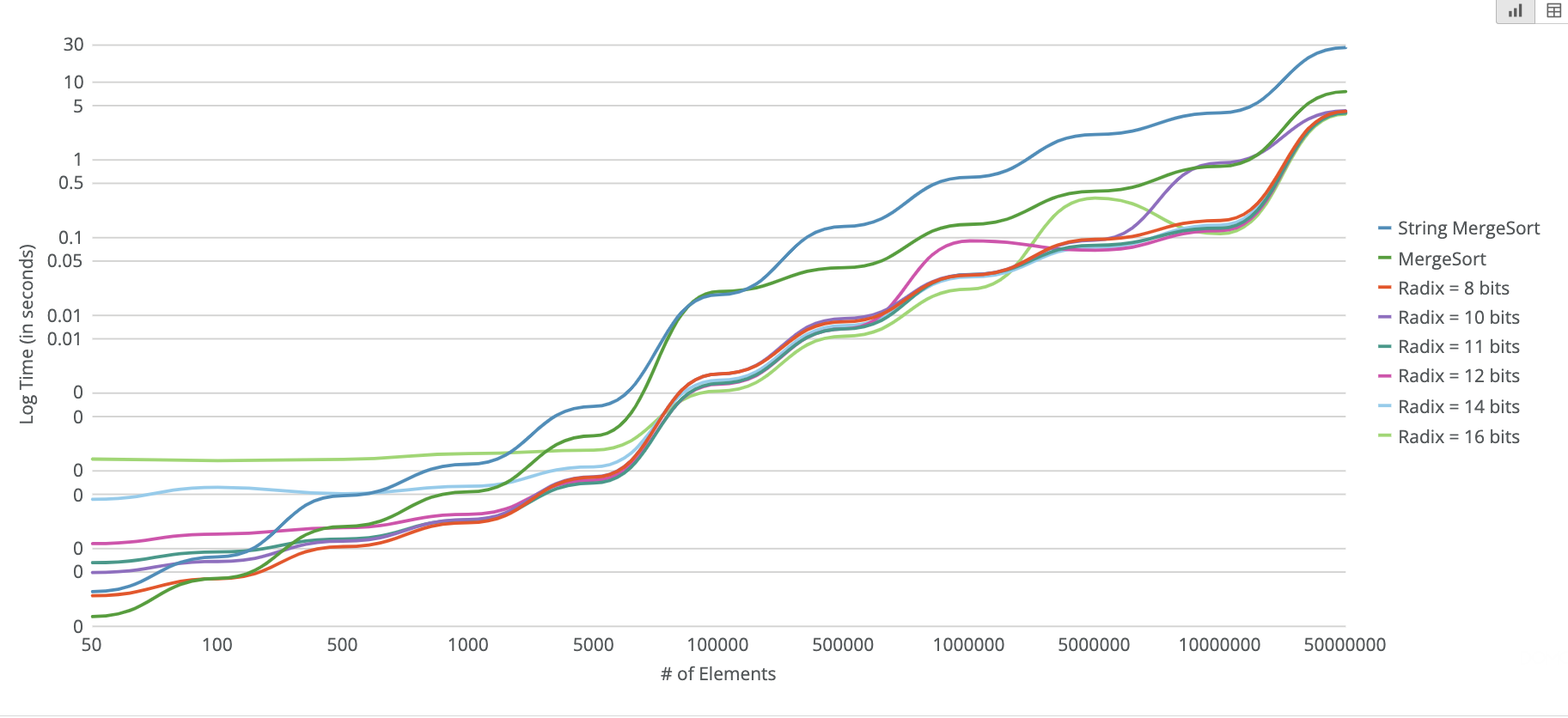
Note the time axis here is log scale, so for the really large arrays, radix sort provides an extremely large performance improvement.
Future work
Ok, this all sounds really cool, but where does the rubber meet the road here? Well, the latest 0.9 release of CSV.jl now has the default of returning small enough string columns as an inline string type. And inline strings are a natural fit for lots of data formats where strings have a fixed size, including the many database systems and their VARCHAR(32), for example.
Another piece of future work I've started thinking about is having more "inline-string-native" string operations, as requested in this issue. For example, reverse(::InlineString) should certainly be able to return an inline string of the same size with codepoints reversed, as opposed to using the same Base.reverse implementation and returning a String. The current downside is that if you do certain string operations on an array of inline strings, you may end up with an array of Strings, and lose any GC advantage you may have had. The simplest code example of this would be if I have x where x is a Vector{String15}, and then I do y = map(reverse, x).
If anyone feels so inclined, feel free to jump in on that InlineStrings.jl repo issue if you'd like to take a stab at making a Base string function operate natively on inline strings!
Well, I hope this has been informative. I've known in my head that there were all these juicy details that make this a fun package and I've just needed to take the time, organize them, and get them all out "on paper". As always, feel free to reach out on twitter or come hang with us on the #data julialang slack channel to chat more about all this.